- 首页
- 1. SQLite简介
- 2. SQLite体系结构
-
3.
进程模型
- 3.1. 什么是VDBE
- 3.2. VDBE执行方法
-
3.3.
SQLite执行与VDBE
- 3.3.1. OP_Init
- 3.3.2. OP_Transaction
- 3.3.3. OP_TableLock
- 3.3.4. OP_Goto
- 3.3.5. OP_ReadCookie
- 3.3.6. OP_If
- 3.3.7. OP_Integer1
- 3.3.8. OP_SetCookie
- 3.3.9. OP_Integer2
- 3.3.10. OP_SetCookie
- 3.3.11. OP_CreateTable
- 3.3.12. OP_OpenWrite
- 3.3.13. OP_NewRowid
- 3.3.14. OP_Null1
- 3.3.15. OP_Insert
- 3.3.16. OP_Close1
- 3.3.17. OP_Close2
- 3.3.18. OP_Null2
- 3.3.19. OP_OpenWrite1
- 3.3.20. OP_MustBeInt
- 3.3.21. OP_NotExists
- 3.3.22. OP_Rowid
- 3.3.23. OP_IsNull
- 3.3.24. OP_String
- 3.3.25. OP_String1
- 3.3.26. OP_String2
- 3.3.27. OP_Copy
- 3.3.28. OP_String3
- 3.3.29. OP_MakeRecord
- 3.3.30. OP_Insert1
- 3.3.31. OP_Close3
- 3.3.32. OP_Integer3
- 3.3.33. OP_SetCookie1
- 3.3.34. OP_ParseSchema
- 3.3.35. OP_Halt
- 3.4. SQLite执行过程
- 3.5. vdbeaux.c源码概览
-
3.6.
vdbeaux.c 源码介绍与分析
- 3.6.1. 创建vdbe结构体
- 3.6.2. vdbe准备阶段
- 3.6.3. debug模式
- 3.6.4. 分配空间
- 3.6.5. 初始化vdbe
- 3.6.6. 执行前的准备
- 3.6.7. 释放资源
-
3.6.8.
vdbe执行中的处理
- 3.6.8.1. 函数sqlite3VdbeHalt
- 3.6.8.2. 函数sqlite3VdbeResetStepResult
- 3.6.8.3. 函数sqlite3VdbeTransferError
- 3.6.8.4. 函数sqlite3VdbeReset
- 3.6.8.5. 函数sqlite3VdbeFinalize
- 3.6.8.6. 函数sqlite3VdbeDeleteObject和sqlite3VdbeDelete
- 3.6.8.7. 函数sqlite3VdbeCursorMoveto
- 3.6.8.8. 函数u64 floatSwap
- 3.6.8.9. 函数sqlite3VdbeSerialPut
- 3.6.8.10. 函数sqlite3VdbeAllocUnpackedRecord
- 3.6.8.11. 函数sqlite3ExpirePreparedStatements
- 3.6.8.12. 函数sqlite3VdbeSetVarmask
- 3.7. vdbesort.c源码概览
-
4.
关系查询处理器
- 4.1. 查询解析和授权
- 4.2. 查询重写
- 4.3. 查询优化器
-
4.4.
查询执行器
- 4.4.1. 数据修改语句
-
4.4.2.
Build.c分析
- 4.4.2.1. 实现的功能
-
4.4.2.2.
具体功能的实现
- 4.4.2.2.1. 表的创建
- 4.4.2.2.2. 表的删除
- 4.4.2.2.3. 与表相关的操作
- 4.4.2.2.4. 视图的创建
- 4.4.2.2.5. 索引的创建
- 4.4.2.2.6. 索引的删除
- 4.4.2.2.7. 释放索引(与删除索引相关)
- 4.4.2.2.8. 与索引相关的其他操作
- 4.4.2.2.9. ID序列的创建
- 4.4.2.2.10. ID序列的删除
- 4.4.2.2.11. ID序列其他操作
- 4.4.2.2.12. 事务的开始
- 4.4.2.2.13. 事务的提交
- 4.4.2.2.14. 事务的回滚
- 4.4.2.2.15. 临时数据库
- 4.4.2.2.16. 写操作
- 4.4.2.2.17. 异常检查
-
4.4.3.
Insert.c解析
- 4.4.3.1. insert的主要关系
- 4.4.3.2. sqlite3OpenTable()
- 4.4.3.3. sqlite3IndexAffinityStr()
- 4.4.3.4. sqlite3TableAffinityStr()
- 4.4.3.5. static int readsTable()
- 4.4.3.6. static int autoIncBegin()
- 4.4.3.7. void sqlite3AutoincrementBegin()
- 4.4.3.8. static void autoIncStep()
- 4.4.3.9. sqlite3AutoincrementEnd()
- 4.4.3.10. xferOptimization()
- 4.4.3.11. sqlite3Insert()
- 4.4.3.12. sqlite3GenerateConstraintChecks()
- 4.4.3.13. sqlite3CompleteInsertion()
- 4.4.3.14. sqlite3OpenTableAndIndices()
- 4.4.3.15. xferCompatibleCollation()
- 4.4.3.16. xferCompatibleIndex()
- 4.4.4. 分析delete.c和update.c
- 4.4.5. Delete.c中主要函数的实现及功能
- 4.4.6. Update.c简介
- 4.4.7. Update.c中主要函数的实现及功能
- 4.4.8. Trigger.c
- 4.4.9. 实现修改表功能ALTER TABLE(alter.c的源码分析)
- 4.5. 生成,清空,删除SELECT查询树函数
- 4.6. 数据库扩展性
- 4.7. 在SQLite3下查询数据
- 4.8. 其它一些函数的功能
- 5. 存储管理
- 6. 事务:并发控制和恢复
-
7.
共享组件
- 7.1. 目录管理器
- 7.2. 内存分配器
-
7.3.
其他工具
- 7.3.1. SqliteLimite.h
- 7.3.2. SqliteInt.h
- 7.3.3. Global.c模块源码分析
- 7.3.4. 主函数分析
-
7.3.5.
Printf.c分析
- 7.3.5.1. 数据类型定义
- 7.3.5.2. sqlite3AppendSpace()函数
- 7.3.5.3. sqlite3VXPrintf()函数
- 7.3.5.4. sqlite3StrAccumAppend()函数
- 7.3.5.5. *sqlite3StrAccumFinish()函数
- 7.3.5.6. sqlite3StrAccumReset()函数
- 7.3.5.7. sqlite3StrAccumInit()函数
- 7.3.5.8. *sqlite3VMPrintf()函数
- 7.3.5.9. *sqlite3MPrintf()函数
- 7.3.5.10. *sqlite3MAppendf()函数
- 7.3.5.11. *sqlite3_vmprintf()函数
- 7.3.5.12. *sqlite3_mprintf()函数
- 7.3.5.13. *sqlite3_vsnprintf()函数;*sqlite3_snprintf()函数
- 7.3.5.14. renderLogMsg()函数
- 7.3.5.15. sqlite3_log()函数
- 7.3.5.16. sqlite3DebugPrintf()函数
- 7.3.5.17. sqlite3XPrintf()函数
- 7.3.6. date.c模块源码分析
- 7.3.7. util.c分析
- 7.3.8. utf.c分析
- 7.3.9. Ctime.c模块源码分析
- 7.3.10. Printf.c
- 7.3.11. date.c模块源码分析(1)
- 7.3.12. date.c模块源码分析(2)
- 7.3.13. forexample
- 7.4. complete.c模块源码分析
- 7.5. callback.c模块源码分析
- 7.6. Hash
- 7.7. Sqlite源代码介绍
- 8. Shell模式下使用CLP
- 9. 实现SQL的各种函数(func.c的源码分析)
- Generated using GitBook
索引的组织结构
在全文检索中,我们需要先知道索引里面存的是什么?在此之前,有必要先来分析一下,顺序扫描速度慢的真正原因。先从用户的角度来考虑,用户提出的查询请求实际上可以认为用户想说的是那写文字中有我要找的字符串,从映射的角度来说,用户的查询请求可以认为是从字符串到文件的一个映射,而对于非结构化内容的文件来说,他能告诉的是,我的文件内容中有没有包含用户要查询的字符串,文件知道的和用户查询的刚好回一个相反的映射关系这样的一个反向关系是顺序扫描慢的一个原因。
索引解决的实际上就是将两者的关系同步的问题,由于用于的查询请求是无法改变映射方向的,那么索引实际上解决的是将文件的映射关系反转,所以索引又被称为反向索引。
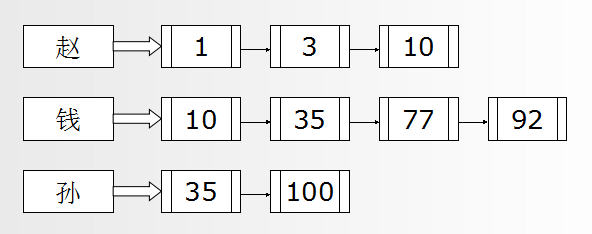
左边的字符串列表称为词典。在每个字符串后面有一个由文档编号所构成的单链表,在这个单链表中的文档,表示该文档包含左侧对应词典中的单词。这个单链表又称为倒排表。正因为有这样的索引结构,它保证了用户信息的映射关系和文档映射关系一致。
这个时候如果用户要查找及包含“孙”也包含“赵”的文档, (1)在索引中查找到字符串“孙”,并取出它所对应的倒排表
(2)在索引中查找到字符串“赵”,并取出它所对应的倒排表
(3)合并以上的两个倒排表,也就是找出两个链表中相同编号的文档集合,这样最终的文档集合就是既包含了“孙”又包含了“赵”了。