- 首页
- 1. SQLite简介
- 2. SQLite体系结构
-
3.
进程模型
- 3.1. 什么是VDBE
- 3.2. VDBE执行方法
-
3.3.
SQLite执行与VDBE
- 3.3.1. OP_Init
- 3.3.2. OP_Transaction
- 3.3.3. OP_TableLock
- 3.3.4. OP_Goto
- 3.3.5. OP_ReadCookie
- 3.3.6. OP_If
- 3.3.7. OP_Integer1
- 3.3.8. OP_SetCookie
- 3.3.9. OP_Integer2
- 3.3.10. OP_SetCookie
- 3.3.11. OP_CreateTable
- 3.3.12. OP_OpenWrite
- 3.3.13. OP_NewRowid
- 3.3.14. OP_Null1
- 3.3.15. OP_Insert
- 3.3.16. OP_Close1
- 3.3.17. OP_Close2
- 3.3.18. OP_Null2
- 3.3.19. OP_OpenWrite1
- 3.3.20. OP_MustBeInt
- 3.3.21. OP_NotExists
- 3.3.22. OP_Rowid
- 3.3.23. OP_IsNull
- 3.3.24. OP_String
- 3.3.25. OP_String1
- 3.3.26. OP_String2
- 3.3.27. OP_Copy
- 3.3.28. OP_String3
- 3.3.29. OP_MakeRecord
- 3.3.30. OP_Insert1
- 3.3.31. OP_Close3
- 3.3.32. OP_Integer3
- 3.3.33. OP_SetCookie1
- 3.3.34. OP_ParseSchema
- 3.3.35. OP_Halt
- 3.4. SQLite执行过程
- 3.5. vdbeaux.c源码概览
-
3.6.
vdbeaux.c 源码介绍与分析
- 3.6.1. 创建vdbe结构体
- 3.6.2. vdbe准备阶段
- 3.6.3. debug模式
- 3.6.4. 分配空间
- 3.6.5. 初始化vdbe
- 3.6.6. 执行前的准备
- 3.6.7. 释放资源
-
3.6.8.
vdbe执行中的处理
- 3.6.8.1. 函数sqlite3VdbeHalt
- 3.6.8.2. 函数sqlite3VdbeResetStepResult
- 3.6.8.3. 函数sqlite3VdbeTransferError
- 3.6.8.4. 函数sqlite3VdbeReset
- 3.6.8.5. 函数sqlite3VdbeFinalize
- 3.6.8.6. 函数sqlite3VdbeDeleteObject和sqlite3VdbeDelete
- 3.6.8.7. 函数sqlite3VdbeCursorMoveto
- 3.6.8.8. 函数u64 floatSwap
- 3.6.8.9. 函数sqlite3VdbeSerialPut
- 3.6.8.10. 函数sqlite3VdbeAllocUnpackedRecord
- 3.6.8.11. 函数sqlite3ExpirePreparedStatements
- 3.6.8.12. 函数sqlite3VdbeSetVarmask
- 3.7. vdbesort.c源码概览
-
4.
关系查询处理器
- 4.1. 查询解析和授权
- 4.2. 查询重写
- 4.3. 查询优化器
-
4.4.
查询执行器
- 4.4.1. 数据修改语句
-
4.4.2.
Build.c分析
- 4.4.2.1. 实现的功能
-
4.4.2.2.
具体功能的实现
- 4.4.2.2.1. 表的创建
- 4.4.2.2.2. 表的删除
- 4.4.2.2.3. 与表相关的操作
- 4.4.2.2.4. 视图的创建
- 4.4.2.2.5. 索引的创建
- 4.4.2.2.6. 索引的删除
- 4.4.2.2.7. 释放索引(与删除索引相关)
- 4.4.2.2.8. 与索引相关的其他操作
- 4.4.2.2.9. ID序列的创建
- 4.4.2.2.10. ID序列的删除
- 4.4.2.2.11. ID序列其他操作
- 4.4.2.2.12. 事务的开始
- 4.4.2.2.13. 事务的提交
- 4.4.2.2.14. 事务的回滚
- 4.4.2.2.15. 临时数据库
- 4.4.2.2.16. 写操作
- 4.4.2.2.17. 异常检查
-
4.4.3.
Insert.c解析
- 4.4.3.1. insert的主要关系
- 4.4.3.2. sqlite3OpenTable()
- 4.4.3.3. sqlite3IndexAffinityStr()
- 4.4.3.4. sqlite3TableAffinityStr()
- 4.4.3.5. static int readsTable()
- 4.4.3.6. static int autoIncBegin()
- 4.4.3.7. void sqlite3AutoincrementBegin()
- 4.4.3.8. static void autoIncStep()
- 4.4.3.9. sqlite3AutoincrementEnd()
- 4.4.3.10. xferOptimization()
- 4.4.3.11. sqlite3Insert()
- 4.4.3.12. sqlite3GenerateConstraintChecks()
- 4.4.3.13. sqlite3CompleteInsertion()
- 4.4.3.14. sqlite3OpenTableAndIndices()
- 4.4.3.15. xferCompatibleCollation()
- 4.4.3.16. xferCompatibleIndex()
- 4.4.4. 分析delete.c和update.c
- 4.4.5. Delete.c中主要函数的实现及功能
- 4.4.6. Update.c简介
- 4.4.7. Update.c中主要函数的实现及功能
- 4.4.8. Trigger.c
- 4.4.9. 实现修改表功能ALTER TABLE(alter.c的源码分析)
- 4.5. 生成,清空,删除SELECT查询树函数
- 4.6. 数据库扩展性
- 4.7. 在SQLite3下查询数据
- 4.8. 其它一些函数的功能
- 5. 存储管理
- 6. 事务:并发控制和恢复
-
7.
共享组件
- 7.1. 目录管理器
- 7.2. 内存分配器
-
7.3.
其他工具
- 7.3.1. SqliteLimite.h
- 7.3.2. SqliteInt.h
- 7.3.3. Global.c模块源码分析
- 7.3.4. 主函数分析
-
7.3.5.
Printf.c分析
- 7.3.5.1. 数据类型定义
- 7.3.5.2. sqlite3AppendSpace()函数
- 7.3.5.3. sqlite3VXPrintf()函数
- 7.3.5.4. sqlite3StrAccumAppend()函数
- 7.3.5.5. *sqlite3StrAccumFinish()函数
- 7.3.5.6. sqlite3StrAccumReset()函数
- 7.3.5.7. sqlite3StrAccumInit()函数
- 7.3.5.8. *sqlite3VMPrintf()函数
- 7.3.5.9. *sqlite3MPrintf()函数
- 7.3.5.10. *sqlite3MAppendf()函数
- 7.3.5.11. *sqlite3_vmprintf()函数
- 7.3.5.12. *sqlite3_mprintf()函数
- 7.3.5.13. *sqlite3_vsnprintf()函数;*sqlite3_snprintf()函数
- 7.3.5.14. renderLogMsg()函数
- 7.3.5.15. sqlite3_log()函数
- 7.3.5.16. sqlite3DebugPrintf()函数
- 7.3.5.17. sqlite3XPrintf()函数
- 7.3.6. date.c模块源码分析
- 7.3.7. util.c分析
- 7.3.8. utf.c分析
- 7.3.9. Ctime.c模块源码分析
- 7.3.10. Printf.c
- 7.3.11. date.c模块源码分析(1)
- 7.3.12. date.c模块源码分析(2)
- 7.3.13. forexample
- 7.4. complete.c模块源码分析
- 7.5. callback.c模块源码分析
- 7.6. Hash
- 7.7. Sqlite源代码介绍
- 8. Shell模式下使用CLP
- 9. 实现SQL的各种函数(func.c的源码分析)
- Generated using GitBook
全文检索(full-text search)
4.1简介
全文检索技术实际上在很多地方早有应用,例如在管理图书馆图书的时候,会使用书签来标识图书的内容,而这个标志来自对图书内容的概括和分类,有时候也直接取图书中的关键字段来标识图书。然后这仅仅只是全文枷锁的简单应用,如今海量网络数据,要想在这海量数据中搜索想要的知识,仅仅只靠提取网页中的几个关键字来标识数据往往得不到准确地数据,因此而应运而生了像Google这样的专业搜索公司。下面就是全文检索的过程。
首先来说说倒排索引和倒排表为什么我们要说倒排索引呢?
因为倒排索引是目前 搜索引擎公司最对搜索引擎最常用的存储方式.也是搜索引擎的核心内容!在搜索引擎实际的应用之中,有时需要按照关键字的某些值查找记录,所以我们是按照关键字建立索引,这个索引我们就称之为: 倒排索引, 而带有倒排索引的文件我们又称作: 倒排索引文件,也可以叫它为: 倒排文件。用它来实现快速的检索与高速的效率!
倒排文件中的次关键字索引,我们称做: 倒排表。其主要优点是:
在处理复杂的多关键字查询时,可在倒排表中先完成查询的交、并等逻辑运算,得到结果后再对记录进行存取。这样不必对每个记录随机存取,把对记录的查询转换为地址集合的运算,从而提高查找速度!
4.2工作原理
实现全文检索工作原理如下图:
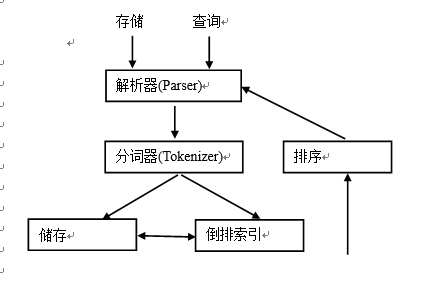
当存储一条文档数据时,解析器与分词器将该文档数据划分成各自独立的词项,并为每个词项建立一个倒排索引。当查询时,解析器与分词器将查询数据进行词项划分,然后遍历倒排索引,找到其相应的记录号,最后根据与查询条件的相关性等排序规则,返回结果集。
FTS虚表的使用方法同普通表类似,可以进行插入、删除、修改等操作。创建具有title、contents两个TEXT类型的字段,使用Porter内置分词器虚表sms的SQL语句如下:
CREATE VIRTUAL TABLE sms USING fts1(title,contents.tokenize=porter);
使用MATCH关键字对contents字段及其sms虚表的所有字段进行全文检索的SQL语句分别如下:
SELECT title,contents FROM sms WHERE contents MATCH’Let the bullets fly’
SELECT title,contents FROM sms WHERE sms MATCH’Let the bullets fly’
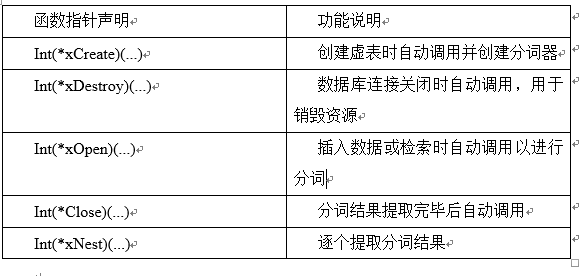
Sqlite3_tokenizer_module结构体定义了自定义分词器实现全文检索所要实现的接口
Sqlite3_tokenizer_module结构体函数指针
一般来说,全文检索需要具备建立索引和提供查询者两项基本功能。功能上,全文检索核心具有建立索引、增加索引、优化索引、处理查询返回结果集等功能。全文检索中索引的组织记录方法有两种,即正排表和倒排表。正排表示以文档的ID为关键词,表中记录项记录文档中每个词的位置信息,查找时扫描表中每个文档中词的信息直到找出所有包含查询关键词的文档。
索引扫描:指非结构化数据经过索引之后形成的结构化数据中,按照顺序扫描的方法进行字符串匹配的过程。
上面的说法比较抽象,举个例子来说,上小学的时候,语文老师叫我们查一个字的读音。在查字典的时候首先会先根据这个字偏旁部首的笔画,找到片片能够不受所在的位置,然后在根据剩下的笔画中查找这个字,找到这个之后就能找到这个字在词典页的位置,然后翻到该页,就能知道这个字的读音了,在字典的最开始收录了整个字典所包含的字,并根据偏旁部首再进行划分,整个查找过程我们仅仅只需要在字典首页的那几页进行查找,而且还有由偏旁部首到具体字的二级映射。
全文检索,就是先建立索引,然后在索引中进行搜索的过程。 创建索引和搜索索引是全文检索的两个必要环节,其中将非结构化数据经过一定的抽取和拼装算法,最后形成结构化数据的过程被称为索引。而搜索索引就是将用户的匹配字符串,在我们事先创建的结构化索引文件中,按顺序扫描,然后将搜索到的结果按照一定的排序算法,返回给用户的过程。由此需要先解决全文检索本身存在的三个关键问题,
①首先是索引里面究竟存的是什么,
②其次如何来生成这个索引,
③最后要如何对索引进行搜索